

In a previous post I looked at mapping deprivation in the different districts of Greater Manchester (GM) using GeoPandas. One limitation of the maps was that they lacked the context that place names can provide. In this post we look at how we can use the Ordnance Survey’s Open Names dataset to add place names to our GeoPandas maps.
The first step is to generate a Shapefile of place names, as points, in GM. The data is downloaded as a set of CSV files covering grid squares in Great Britain. The aim is to extract only those places that are in the GM boundary.
The script is as follows:
#generates a Shapefile of towns and cities within GM using OS Open Names dataset
import os
import csv
import glob
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
from shapely.geometry import Polygon
boundaryDataPath = "C:/test/"
boundaryDataFile = "GM boundary.shp"
dataFilePath = "C:/test/"
headerFileName = "C:/test/OS_Open_Names_Header.csv"
OSnationalGridSquares = ("SD","SE","SJ","SK")
# read the header file
with open(headerFileName, 'r') as headerFile:
header = csv.reader(headerFile)
for row in header:
headers = row
# get a list of relevant files i.e. those that are in the specified grid squares
files = list()
for square in OSnationalGridSquares:
files.extend(glob.glob(os.path.join(dataFilePath, square +'*.csv')))
# get the GM boundary as a polygon...
boundaryTable = gpd.read_file(boundaryDataPath + boundaryDataFile)
GMgeometry = boundaryTable['geometry'][[0]] # this is a GeoPandas GeoSeries...
GMpolygon = Polygon(GMgeometry[0]) # ... we need it as a Shapely polygon
# loop through relevant Open Names CSV files and extract Towns and Cities
townsCities = pd.DataFrame(columns=['NAME1','TYPE','LOCAL_TYPE','GEOMETRY_X','GEOMETRY_Y'])
for filename in files:
dfPlaces = pd.read_csv(filename,names=headers)
dfPlaces = dfPlaces[['NAME1','TYPE','LOCAL_TYPE','GEOMETRY_X','GEOMETRY_Y']]
townsCities = townsCities.append(dfPlaces[(dfPlaces['LOCAL_TYPE'] == 'Town') | (dfPlaces['LOCAL_TYPE'] == 'City')])
# loop through the Towns and Cities and create a list of those within the GM boundary
listGMplaces = list()
for place in townsCities.itertuples(index=True, name='Pandas'):
townCityPoint = Point(place.GEOMETRY_X, place.GEOMETRY_Y)
if townCityPoint.within(GMpolygon):
print ( place.NAME1 + " is within GM" )
listGMplaces.append([place.NAME1,place.TYPE,place.LOCAL_TYPE,townCityPoint])
# create a Shapefile of the Towns and Cities within GM
dfGMplaces = pd.DataFrame(listGMplaces,columns=['NAME1','TYPE','LOCAL_TYPE','GEOMETRY'])
crsOSGB = {'init': 'epsg:27700'}
gpdfGMplaces = gpd.GeoDataFrame(dfGMplaces, crs=crsOSGB, geometry='GEOMETRY')
gpdfGMplaces.to_file(boundaryDataPath + 'GMplaces.shp', driver='ESRI Shapefile')
The CSV files are without headers, so the first step is to read the file that contains the headers (lines 16 to 19). To limit the amount of data read, we are going to limit the search to those grid squares that are overlapped by GM (line 13). We then generate a list of relevant files (lines 22 to 24). There are 97 of these – of the format SK84.csv, SK86.csv etc.
The next step is to get the GM boundary as a Shapely polygon (lines 27 to 29). The OS dataset contains different types of places, but we are only interested in towns and cities; these are extracted into a data frame called townsCities (lines 32 to 36).
The next step is to extract those towns and cities that lie within the GM boundary. This is done by creating a Shapely point from the place name’s co-ordinates (line 41) and testing whether that point lies within the polygon (line 42). If it does then the place is added to a list of relevant places (line 44).
Finally, this list is converted to a dataFrame (line 47), then to a GeoDataFrame (line 49 and, at last, to a Shapefile (line 50). Note that the Shapefile’s Coordinate Reference System is set to OSGB (EPSG:27700).
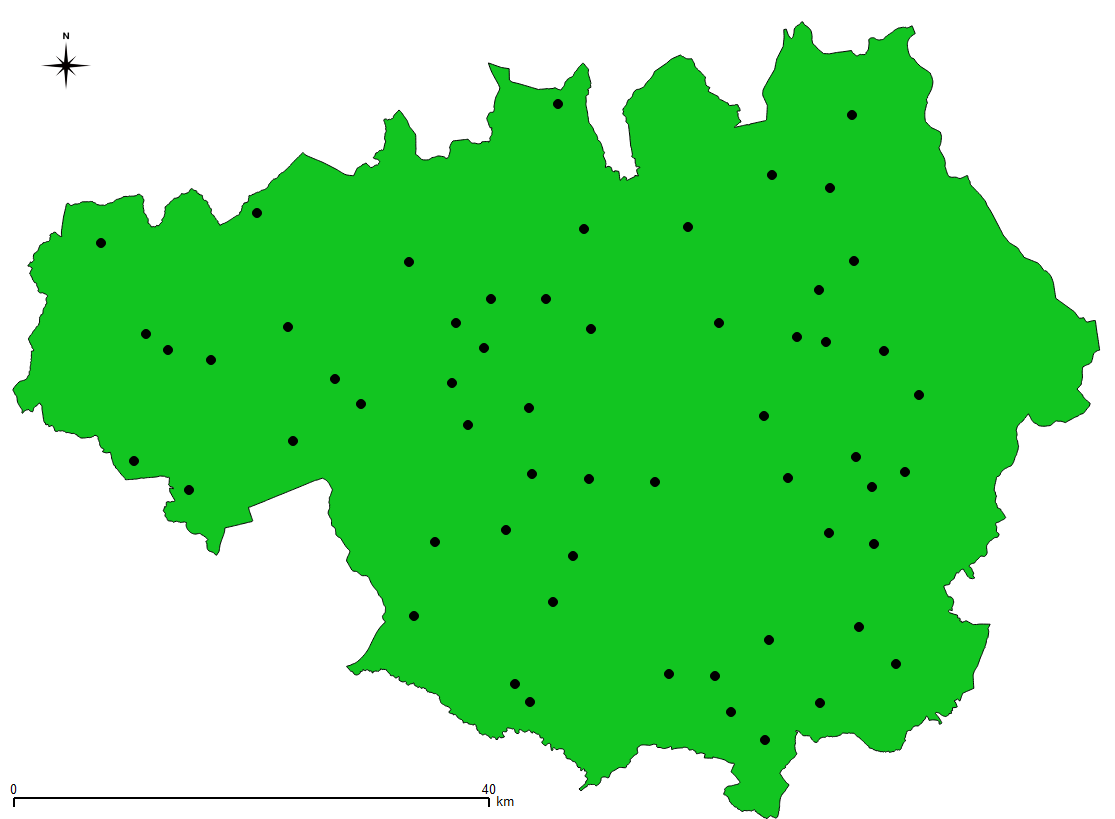
Now that we have a Shapefile of the relevant place names we can add them to the deprivation maps created in an earlier post.
The script is the same as in the earlier post except that we now add place names (the new code is highlighted below).
import geopandas as gpd
import matplotlib.pyplot as plt
import pysal
import rtree
from shapely.geometry import Point
from shapely.geometry import Polygon
sourceDataPath = "C:/test/"
sourceDataFile = "GM_MSOA_deprivation_2011.shp"
placeDataFile = "GMplaces.shp"
# create a geopandas geodataframe...
sourceTable = gpd.read_file(sourceDataPath + sourceDataFile)
placeTable = gpd.read_file(sourceDataPath + placeDataFile)
attributes = {'Total households':'F996','Household is deprived in 4 dimensions':'F1001'}
print ( sourceDataFile + " has " + str(len(sourceTable)) + " records" )
sourceTable['area'] = sourceTable['geometry'].area / 10**6 # area in km squared
for attribute in attributes:
sourceTable[attributes[attribute] + '_density'] = sourceTable[attributes[attribute]] / sourceTable['area']
sourceTable['district'] = sourceTable['name'].str.split(" ").str[0]
districts = sourceTable['district'].unique()
plotNum = 1
for district in districts:
# get data for this district only
districtTable = sourceTable[sourceTable['district'] == district]
print ( str(len(districtTable)) + " MSOAs in " + district )
# get places in this district only using a GeoPandas spatial join
placesInDistrict = gpd.sjoin(placeTable, districtTable, how='inner', op="within")
# the join returns all columns in both tables, so trim down...
placesInDistrict = placesInDistrict[['NAME1','TYPE','LOCAL_TYPE','geometry']]
print ( str(len(placesInDistrict)) + " places in " + district )
for attribute in attributes:
myMap = districtTable.plot(column=attributes[attribute] + '_density',cmap='Reds',scheme='fisher_jenks',edgecolor='black')
placesInDistrict.plot(ax=myMap, marker='o', color='blue', markersize=16) # add places layer to myMap
# add labels to places
for place in placesInDistrict.itertuples(index=True, name='Pandas'):
plt.text(place.geometry.x + 300, place.geometry.y, place.NAME1, bbox=dict(boxstyle='square,pad=0.1', fc='white', ec='none')) # 300m x offset added.
title = attribute + " in " + district
plt.title(title)
plt.figure(plotNum)
plt.savefig(sourceDataPath + title + ".png")
plotNum += 1
plt.show() # NB: call this just once
The places that are within the current district are extracted using a GeoPandas spatial join (line 26). Note that the spatial join requires rtree (line 4). We perform an inner join since we only want to return those rows in both data frames that meet the (spatial) requirement. The join returns all attributes in both datasets so the result is trimmed down to the relevant columns (line 28). For the current district the relevant places are mapped by adding the places to the current plot (myMap) (line 32).
A loop is used to add an offset label to each place marker (lines 34 and 35). The white box behind the label is added using the matplotlib bbox class.
Some sample results can be seen below. Note that more work is required on the placing of labels; for some of the districts (not shown) there is considerable label overlap.

Contains Ordnance Survey data © Crown copyright and database right 2018.
Contains Royal Mail data © Royal Mail copyright and database right 2018.
Contains National Statistics data © Crown copyright and database right 2018.